Collecting Logs with Apache NiFi
It is almost impossible to monitor a large system without aggregating logs and providing a dashboard of visualizations. Many tools and technologies have been created to tackle this problem. Some of the most common open-source approaches to large-scale log aggregation are:
- ElasticSearch + LogStash + Kibana, or ELK for short
- Flume (using MorphlineSolrSink) + Solr + Hue or Banana
- Graylog2 (GELF, Graylog Server, Graylog Web UI)
The remainder of this post will show how to integrate Apache NiFi, Apache Solr, and Banana to create a system for collecting logs. The following diagram shows how the components of the system will interact:
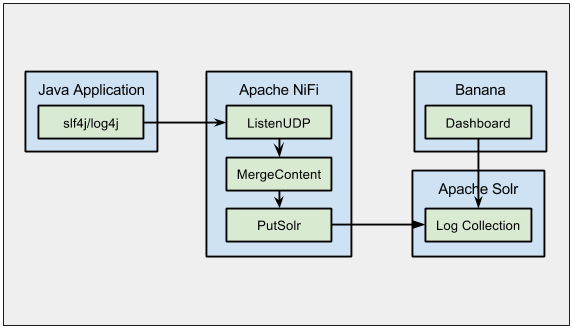
Solr Setup
-
Download the latest Apache Solr release (at this time the latest release is 5.1.0)
-
Extract the Solr distribution and start the cloud example:
tar xzf solr-5.1.0.tgz cd solr-5.1.0 bin/solr start -e cloud -noprompt -
Open http://localhost:8983/solr/#/~cloud in a browser and verify the “gettingstarted” collection is up and running
Banana Setup
-
Clone Banana from GitHub and copy the src directory to Solr’s webapp directory
git clone https://github.com/LucidWorks/banana.git cp -R banana <PATH_TO_SOLR>/solr-5.1.0/server/solr-webapp/webapp/ -
Browse to http://localhost:8983/solr/banana/src/index.html#/dashboard
-
Use the “Configure Dashboard” icon in the top right to change the Solr collection to “gettingstarted”
-
Configure the Time Picker panel and change the field to “_timestamp”
NiFi Setup
Note: This is based off the NiFi develop branch at the time of writing this, as there are some features not yet available in a released version that we need to make use of.
-
Clone the following repository:
git clone https://github.com/apache/incubator-nifi.git cd incubator-nifi git checkout develop -
From here, follow the NiFi Quickstart for building and running NiFi
-
Once NiFi is running, create a simple flow with three processors: ListenUDP, MergeContent, PutSolrContentStream

Configure the processors as follows:
- ListeneUDP
- Set the Port to 8881
- Set Flow File Per Datagram to true
- MergeContent
- Create header.txt with [ in the file, set the Header File property to this file
- Create delimeter.txt with , in the file, set the Demarcator File property to this file
- Create footer.txt with ] in the file, set the Footer File property to this file
- Set the Minimum Number of Entries to 10
- Set the Maximum Number of Entries to 100
- Set the Max Bin Age to 10 seconds
- Auto-terminate the failure and original relationships
Update: As of NiFi 0.2.0 and later, MergeContent has a property called ‘Delimeter Strategy’ which defaults to ‘Filename’. If ‘Delimeter Strategy’ is set to ‘Text’, then the values ([ , ]) can be plugged directly into the corresponding properties of Header, Delimeter, and Footer.
- PutSolrContentStream
- Set the Solr Type to Cloud
- Set the Solr Location to localhost:9983
- Set the Collection to gettingstarted
- Set Commit Within to 1000
- Auto-terminate the failure and success relationships
Producing Logs
To produce logs I created a simple Maven project which uses slf4j+log4j, with a UDP appender, and a logstash JSON layout. The log4j.properties file looks like the following:
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=net.logstash.log4j.JSONEventLayoutV1
log4j.appender.udp=org.apache.log4j.receivers.net.UDPAppender
log4j.appender.udp.remoteHost=localhost
log4j.appender.udp.port=8881
log4j.appender.udp.layout=net.logstash.log4j.JSONEventLayoutV1
log4j.rootLogger=TRACE, stdout, udp
This will send JSON log events to port 8881 where our NiFi ListenUDP processor is listening.
To run this logger, do the following:
git clone https://github.com/bbende/jsonevent-producer.git
cd jsonevent-producer
mvn clean package
java -jar target/jsonevent-producer-1.0-SNAPSHOT.jar <NUM_LOGS> <DELAY_IN_MILLIS>
At this point you should be able to check your Banana dashboard and start seeing events (assuming you have auto-refresh selected):
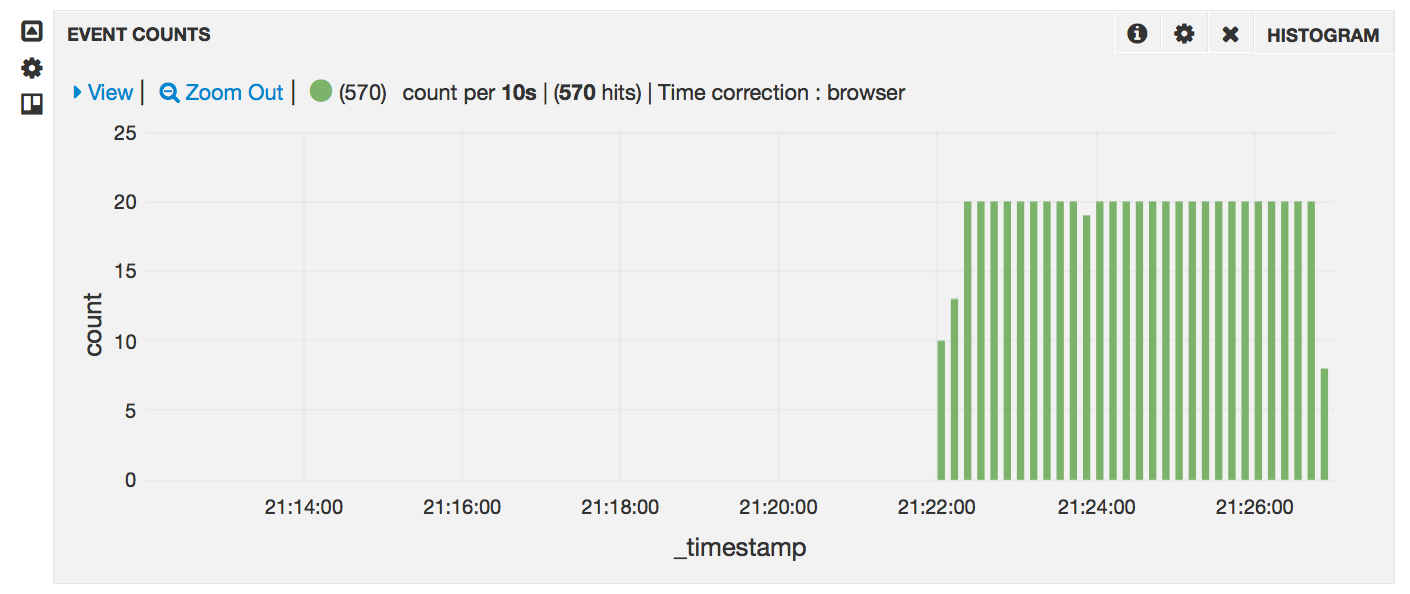
Summary
With a small amount of configuration, and no coding, a simple system for collecting logs can be created. Several approaches could be taken to integrating this into a larger system:
- All nodes in the system could send logs directly to a central NiFi instance over UDP

- Each node producing logs could run a local NiFi instance that aggregates the logs and adds them to Solr

- Each node producing logs could run a local NiFi instance that sends logs to a central instance, which then merges the logs and adds them to Solr

In addition some tuning of the MergeContent processor could be done to achieve the best throughput for adding documents to Solr, and alternatives to UDP could be integrated.
blog comments powered by Disqus