Integrating Apache NiFi and Apache Kafka
Apache Kafka is a high-throughput distributed messaging system that has become one of the most common landing places for data within an organization. Given that Apache NiFi’s job is to bring data from wherever it is, to wherever it needs to be, it makes sense that a common use case is to bring data to and from Kafka. The remainder of this post will take a look at some approaches for integrating NiFi and Kafka, and take a deep dive into the specific details regarding NiFi’s Kafka support.
NiFi as a Producer
A common scenario is for NiFi to act as a Kafka producer. With the advent of the Apache MiNiFi sub-project, MiNiFi can bring data from sources directly to a central NiFi instance, which can then deliver data to the appropriate Kafka topic. The major benefit here is being able to bring data to Kafka without writing any code, by simply dragging and dropping a series of processors in NiFi, and being able to visually monitor and control this pipeline.
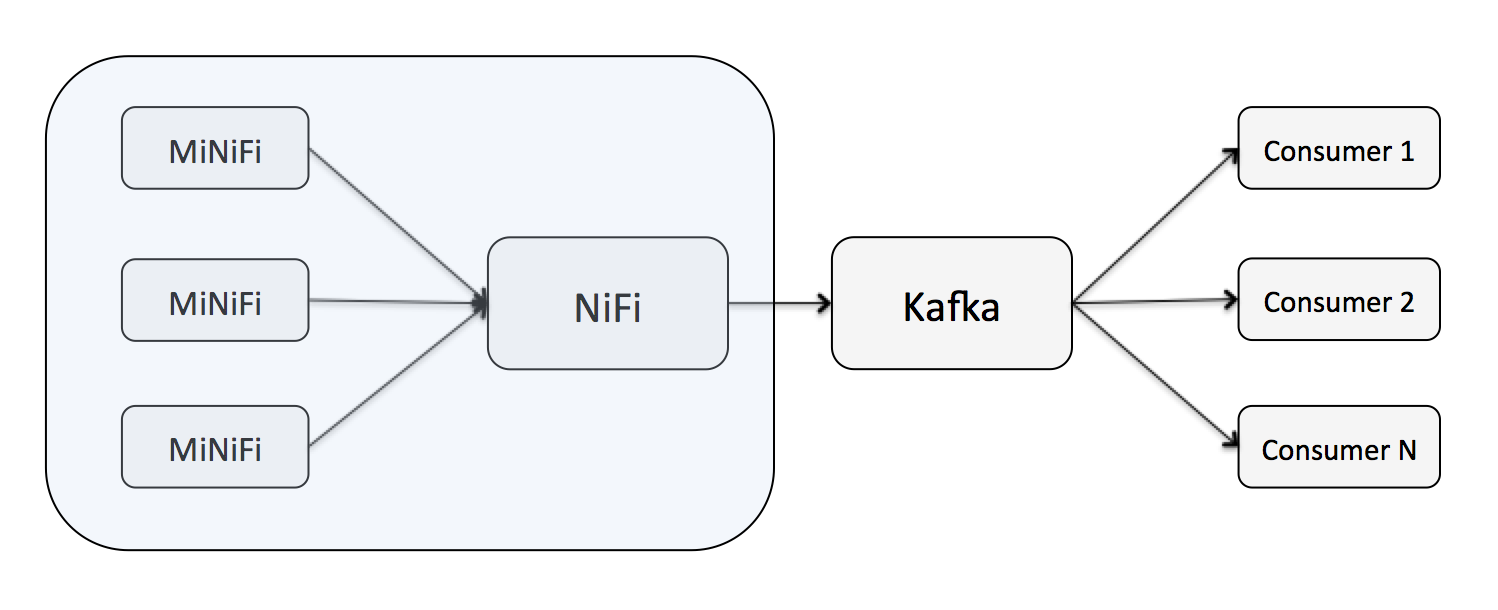
NiFi as a Consumer
In some scenarios an organization may already have an existing pipeline bringing data to Kafka. In this case NiFi can take on the role of a consumer and handle all of the logic for taking data from Kafka to wherever it needs to go. The same benefit as above applies here. For example, you could deliver data from Kafka to HDFS without writing any code, and could make use of NiFi’s MergeContent processor to take messages coming from Kafka and batch them together into appropriately sized files for HDFS.
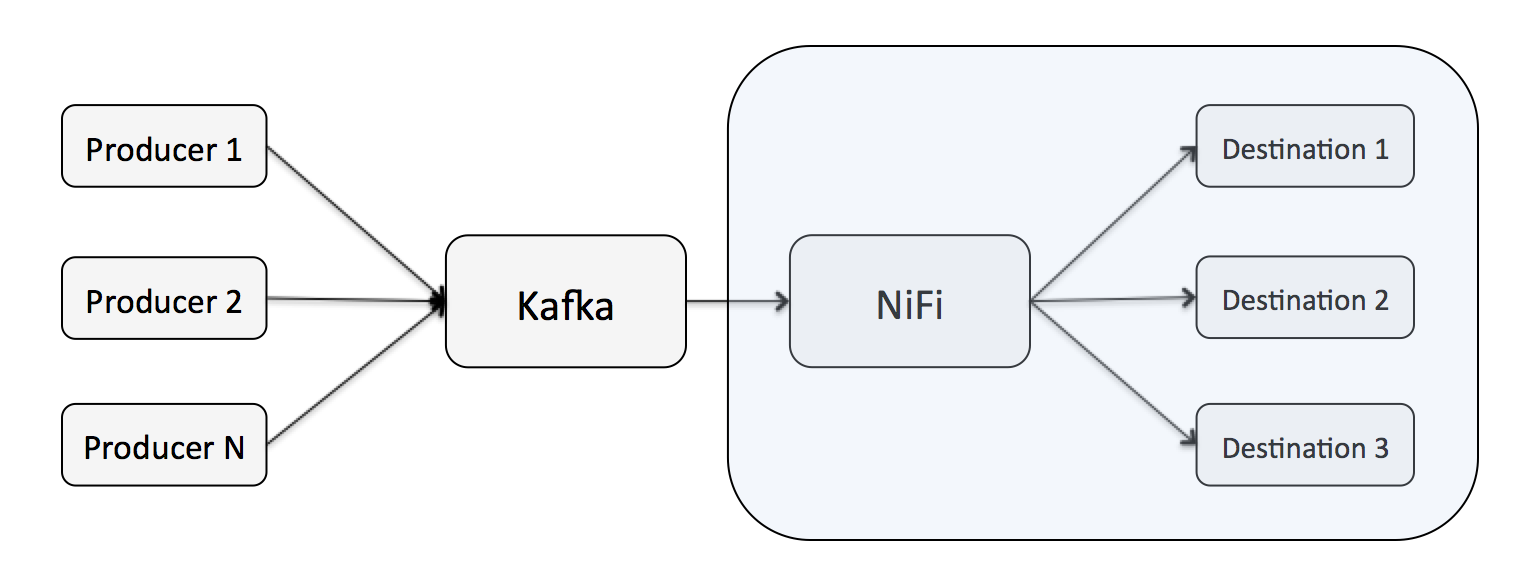
Bi-Directional Data Flows
A more complex scenario could involve combining the power of NiFi, Kafka, and a stream processing platform to create a dynamic self-adjusting data flow. In this case, MiNiFi and NiFi bring data to Kafka which makes it available to a stream processing platform, or other analytic platforms, with the results being written back to a different Kafka topic where NiFi is consuming from, and the results being pushed back to MiNiFi to adjust collection.
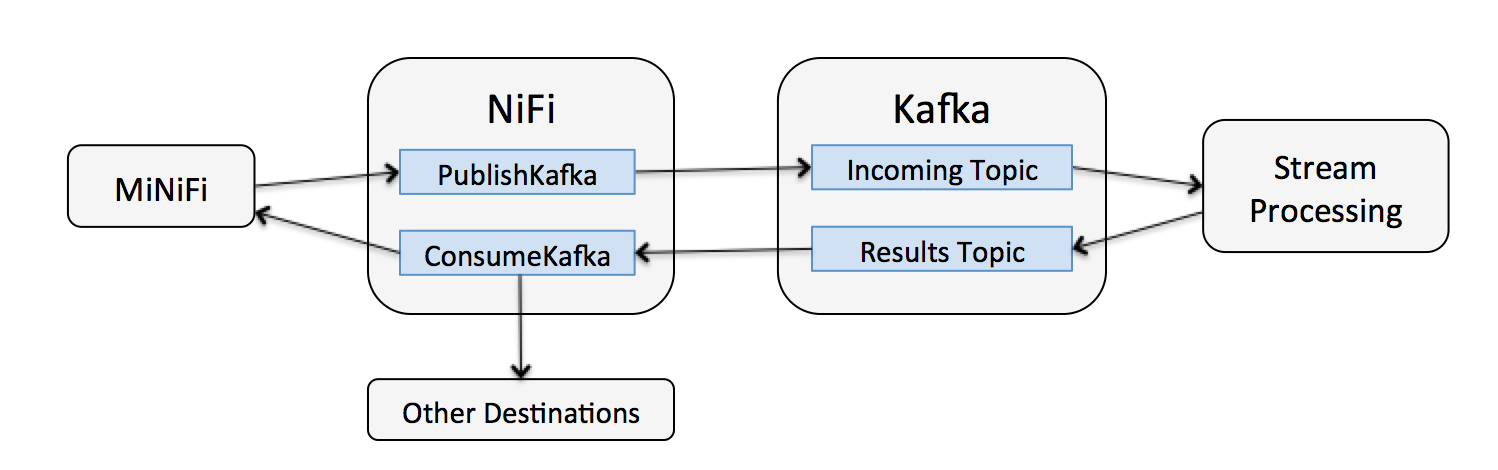
An additional benefit in this scenario is that if we need to do something else with the results, NiFi can deliver this data wherever it needs to go without having to deploy new code.
NiFi’s Kafka Integration
Due to NiFi’s isolated classloading capability, NiFi is able to support multiple versions of the Kafka client in a single NiFi instance. The Apache NiFi 1.0.0 release contains the following Kafka processors:
- GetKafka & PutKafka using the 0.8 client
- ConsumeKafka & PublishKafka using the 0.9 client
- ConsumeKafka_0_10 & PublishKafka_0_10 using the 0.10 client
Which processor to use depends on the version of the Kafka broker that you are communicating with since Kafka does not necessarily provide backward compatibility between versions.
For the rest of this post we’ll focus mostly on the 0.9 and 0.10 processors.
PublishKafka
PublishKafka acts as a Kafka producer and will distribute data to a Kafka topic based on the number of partitions and the configured partitioner, the default behavior is to round-robin messages between partitions. Each instance of PublishKafka has one or more concurrent tasks executing (i.e. threads), and each of those tasks publishes messages independently.
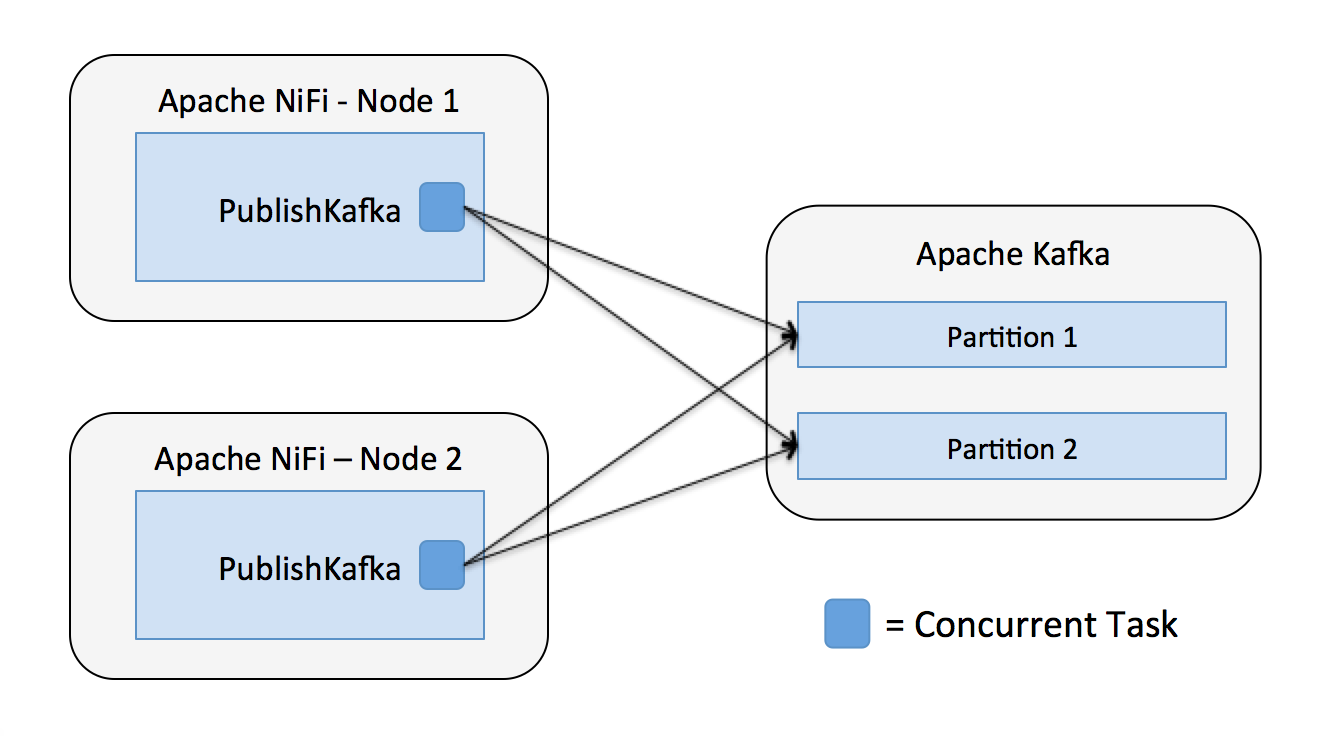
ConsumeKafka
On the consumer side, it is important to understand that Kafka’s client assigns each partition to a specific consumer thread, such that no two consumer threads in the same consumer group will consume from the same partition at the same time. This means that NiFi will get the best performance when the partitions of a topic can be evenly assigned to the concurrent tasks executing the ConsumeKafka processor.
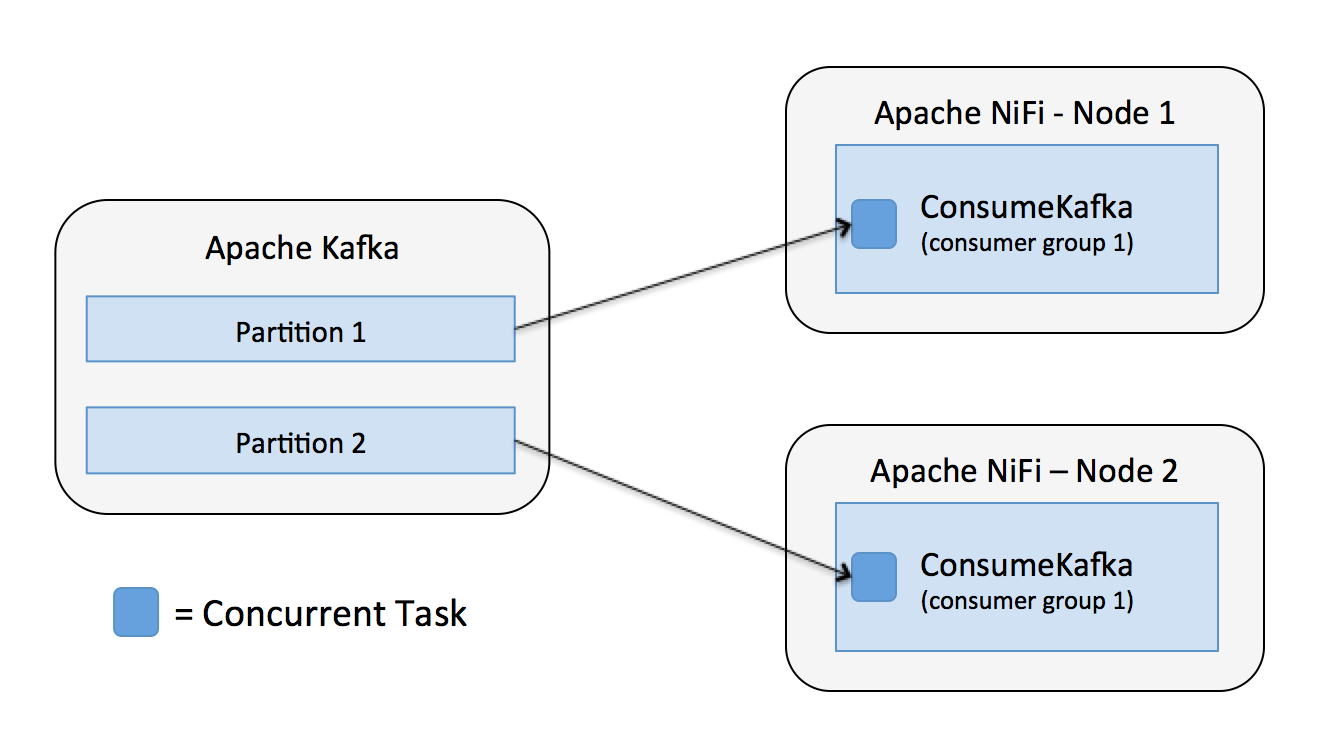
Lets say we have a topic with two partitions and a NiFi cluster with two nodes, each running a ConsumeKafka processor for the given topic. By default each ConsumeKafka has one concurrent task, so each task will consume from a separate partition as shown below.
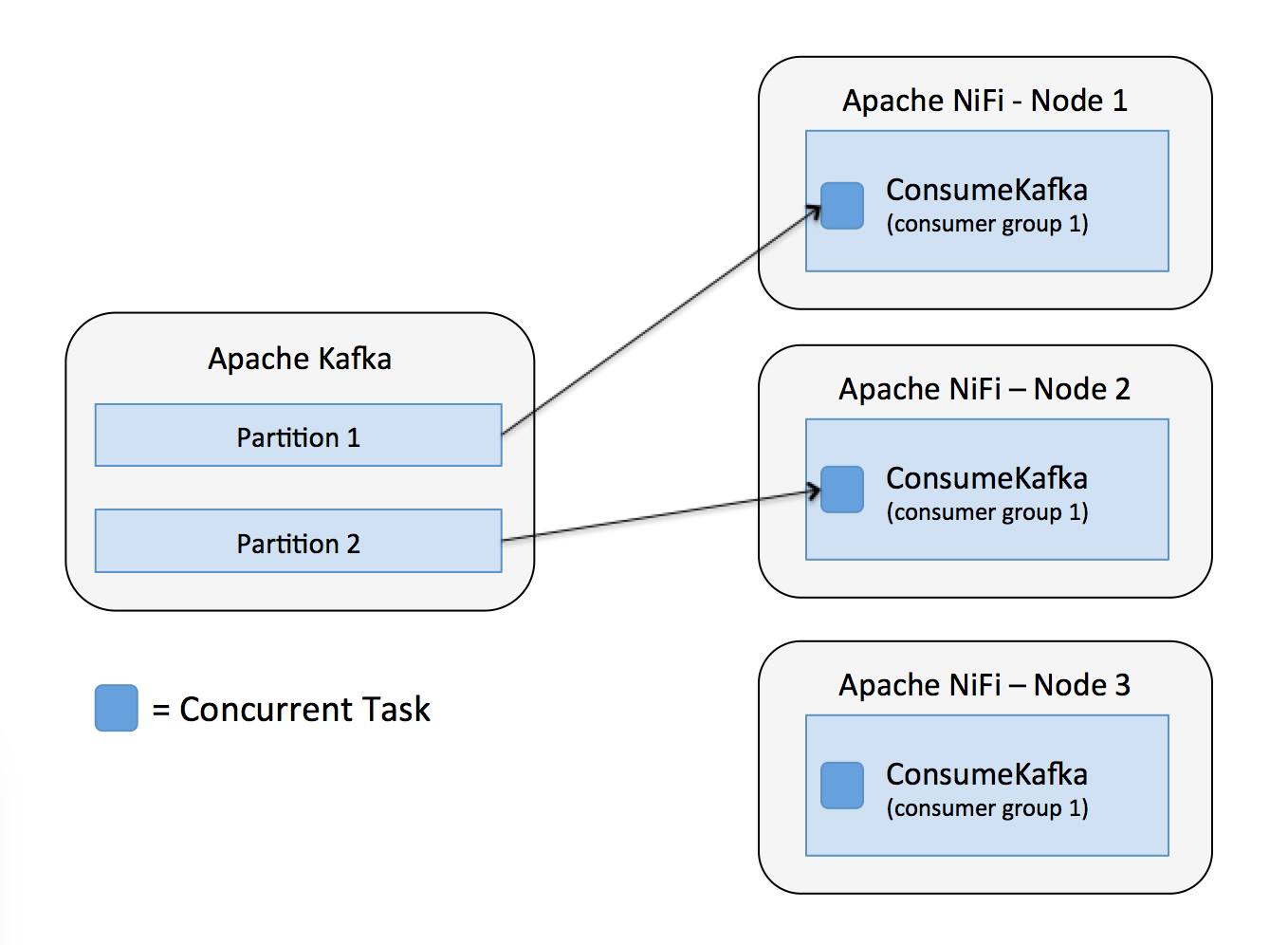
Now lets say we still have one concurrent task for each ConsumeKafka processor, but the number of nodes in our NiFi cluster is greater than the number of partitions in the topic. We would end up with one of the nodes not consuming any data as shown below.
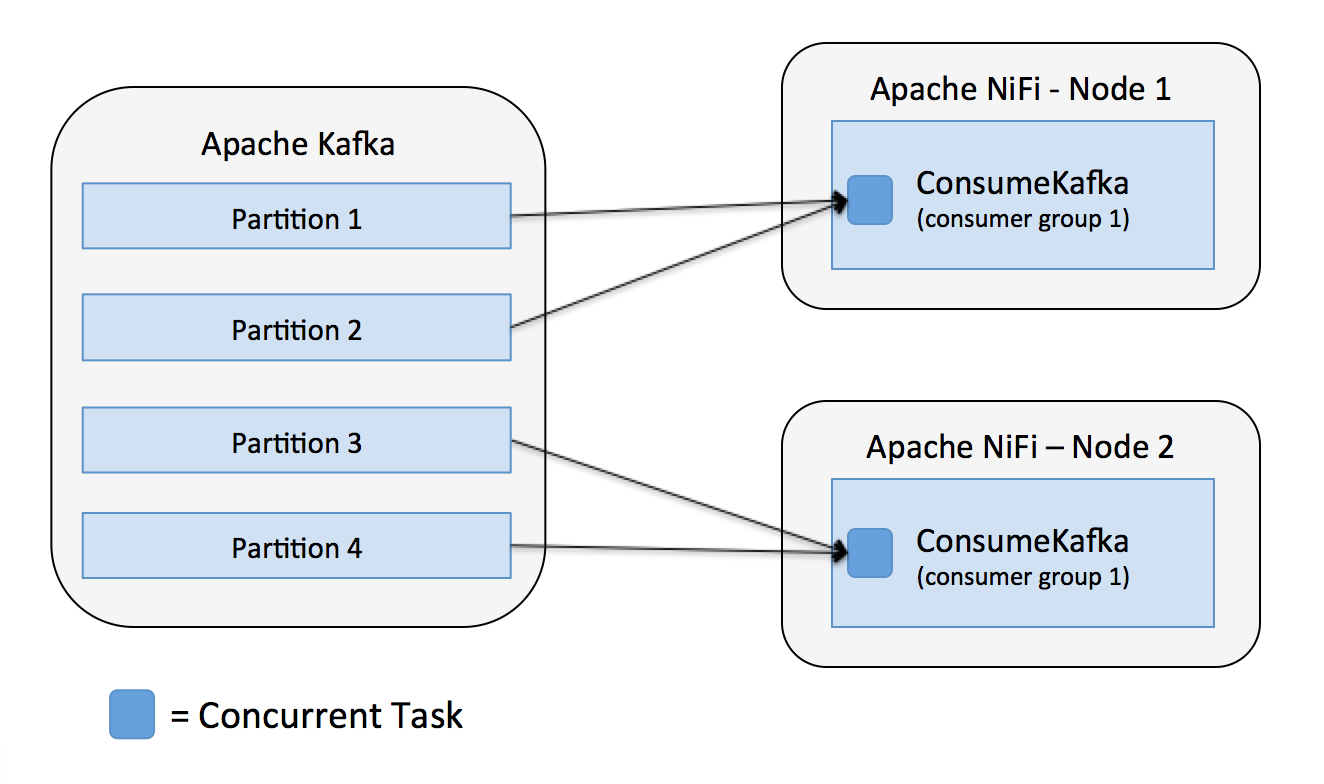
If we have more partitions than nodes/tasks, then each task will consume from multiple partitions. In this case, with four partitions and a two node NiFi cluster with one concurrent task for each ConsumeKafa, each task would consume from two partitions as shown below.
Now if we have two concurrent tasks for each processor, then the number of tasks lines up with the number of partitions, and we get each task consuming from one partition.
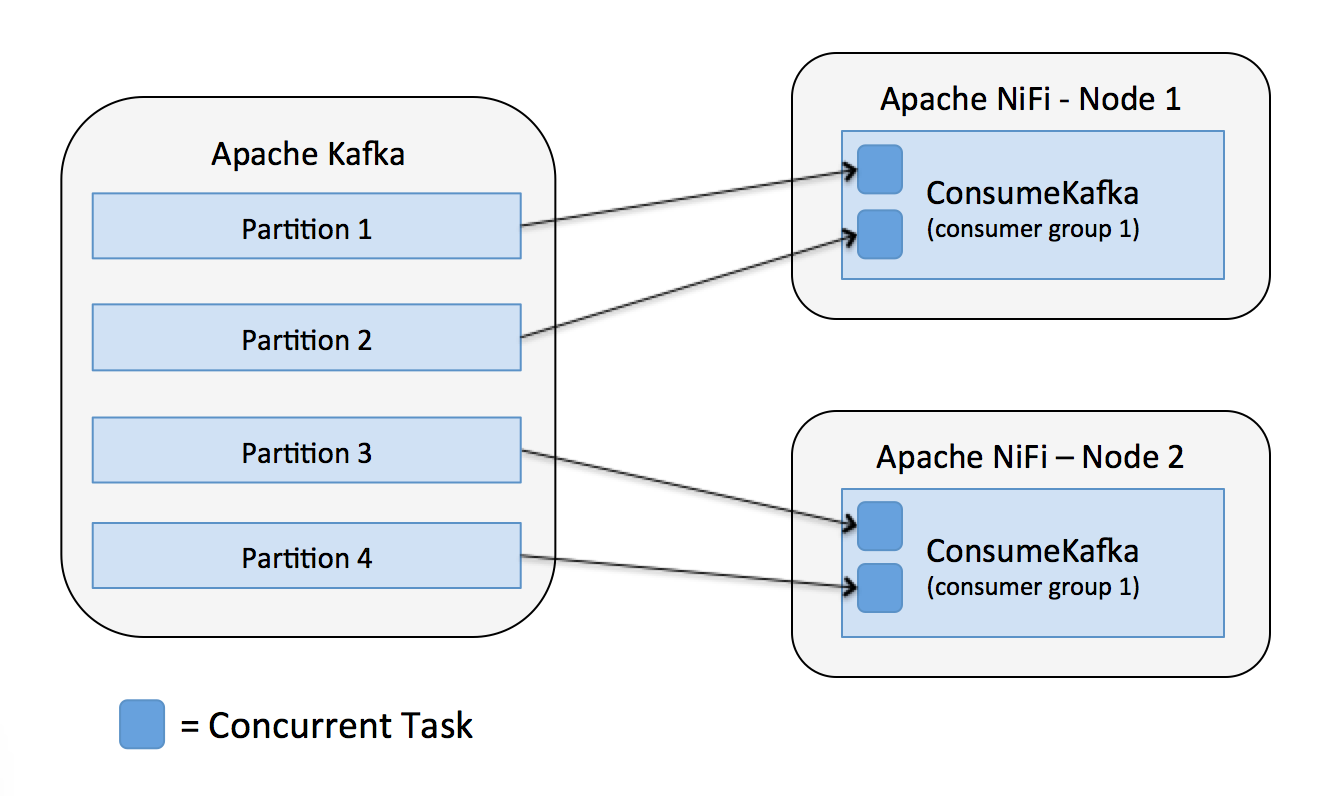
If we had increased the concurrent tasks, but only had two partitions, then some of the tasks would not consume any data. Note, there is no guarantee which of the four tasks would consume data in this case, it is possible it would be two tasks on the same node, and one node not doing anything.
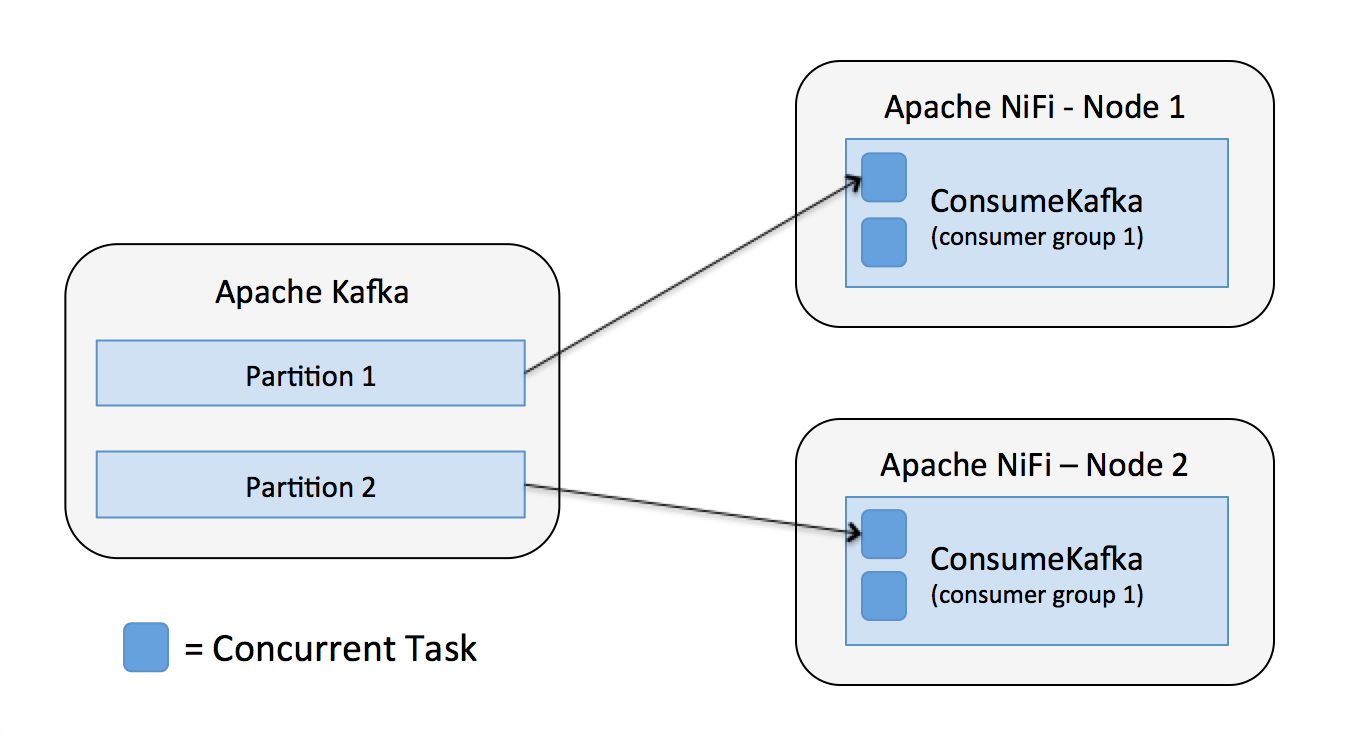
The take-away here is to think about the number of partitions vs. the number of consumer threads in NiFi, and adjust as necessary to create the appropriate balance.
Security
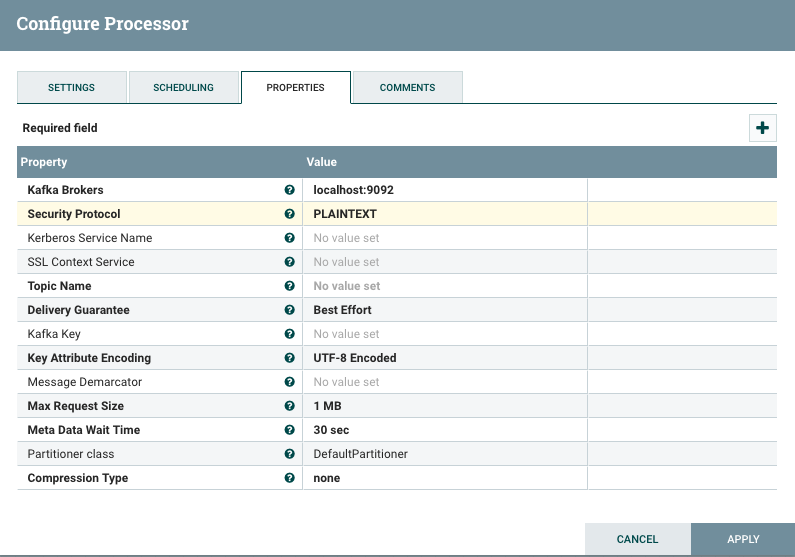
Configuring PublishKafka requires providing the location of the Kafka brokers and the topic name:
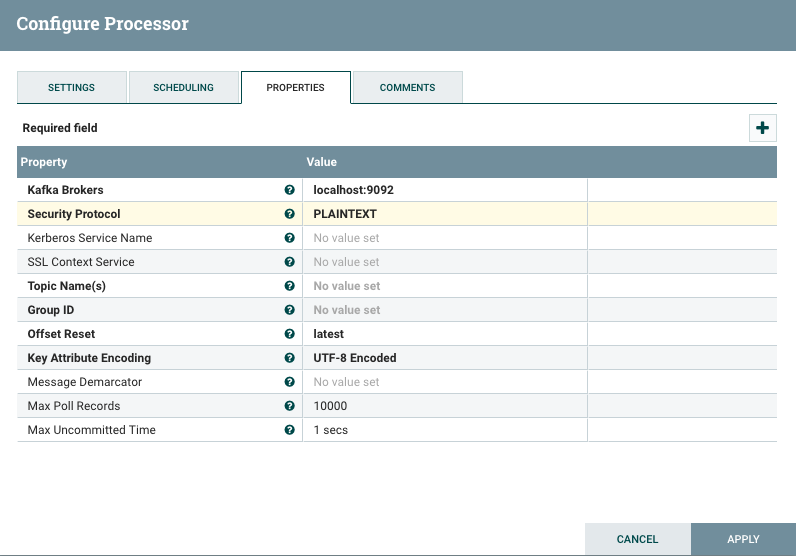
Configuring ConsumeKafka also requires providing the location of the Kafka brokers, and supports a comma-separated list of topic names, or a pattern to match topic names:
Both processors make it easy to setup any of the security scenarios supported by Kafka. This is controlled through the Security Protocol property which has the following options:
- PLAINTEXT
- SSL
- SASL_PLAINTEXT
- SASL_SSL
When selecting SSL, or SASL_SSL, the SSL Context Service must be populated to provide a keystore and truststore as needed.
When selecting SASL_PLAINTEXT, or SASL_SSL, the Kerberos Service Name must be provided, and the JAAS configuration file must be set through a system property in conf/bootstrap.conf with something like the following:
java.arg.15=-Djava.security.auth.login.config=/path/to/jass-client.config
Both processors also support user defined properties that will be passed as configuration to the Kafka producer or consumer, so any configuration that is not explicitly defined as a first class property can still be set.
Performance Considerations
In addition to configuring the number of concurrent tasks as discussed above, there are a couple of other factors that can impact the performance of publishing and consuming in NiFi.
PublishKafka & ConsumeKafka both have a property called “Message Demarcator”.
On the publishing side, the demarcator indicates that incoming flow files will have multiple messages in the content, with the given demarcator between them. In this case, PublishKafka will stream the content of the flow file, separating it into messages based on the demarcator, and publish each message individually. When the property is left blank, PublishKafka will send the content of the flow file as s single message.
On the consuming side, the demarcator indicates that ConsumeKafka should produce a single flow file with the content containing all of the messages received from Kafka in a single poll, using the demarcator to separate them. When this property is left blank, ConsumeKafka will produce a flow file per message received.
Given that Kafka is tuned for smaller messages, and NiFi is tuned for larger messages, these batching capabilities allow for the best of both worlds, where Kafka can take advantage of smaller messages, and NiFi can take advantage of larger streams, resulting in significantly improved performance. Publishing a single flow file with 1 million messages and streaming that to Kafka will be significantly faster than sending 1 million flow files to PublishKafka. The same can be said on the consuming side, where writing a thousand consumed messages to a single flow file will produce higher throughput than writing a thousand flow files with one message each.
blog comments powered by Disqus