Apache NiFi - Records and Schema Registries
Apache NiFi 1.2.0 and 1.3.0 have introduced a series of powerful new features around record processing. There have already been a couple of great blog posts introducing this topic, such as Record-Oriented Data with NiFi and Real-Time SQL on Event Streams. This post will focus on giving an overview of the record-related components and how they work together, along with an example of using an external schema registry.
Record Readers & Writers
The key abstractions introduced to support record processing are the following:
- RecordReader - Reads a flow file as a series of records according to a schema
- RecordReaderFactory - Creates a RecordReader for a given schema
- RecordSetWriter - Writes a series of records to flow file content according to a schema
- RecordSetWriterFactory - Creates a RecordSetWriter for a given schema
- SchemaRegistry - Provides access to schemas by name or id
The RecordReaderFactory and RecordSetWriterFactory are controller services that serve as the gateway to record processing. Any processor that wants to treat flow files as records can provide properties for selecting a RecordReaderFactory and/or RecordSetWriterFactory, and the processor can then focus on interacting with records, and no longer worry about the actual input and output formats. This eliminates the need for many of the ConvertXToY processors because we can now have a ConvertRecord processor that uses any reader and writer.
At the time of writing this post, the following record readers exist:
- AvroReader
- CsvReader
- GrokReader
- JsonPathReader
- JsonTreeReader
- ScriptedReader
At the time of writing this post, the following record writers exist:
- AvroRecordSetWriter
- CsvRecordSetWriter
- JsonRecordSetWriter
- FreeFormTextRecordSetWriter
- ScriptedRecordSetWriter
Detailed descriptions of each can be found in the official Apache NiFi documentation under Controller Services on the left-hand side.
Schemas & Schema Registries
In order to treat the content of a flow file as records, we need a way to interpret that content, and that is done through a schema. A schema defines information about a record, such as the field names, field types, default values, and aliases.
Each reader and writer has a ‘Schema Access Strategy’ which tells it how to obtain a schema, and the options may be different depending on the type of reader or writer.
For example, a CsvReader can choose to create a schema on the fly using the column names from the header of the CSV, and a GrokReader can create a schema from the named parts of the Grok expression, but these two options would only apply to those respective readers.
In general, all readers and writers have the option to use Apache Avro to define a schema, even when the format is not Avro itself. There are several options for obtaining an Avro schema, such as:
- Schema Name - Provide the name of a schema to look up in a Schema Registry
- Schema Text - Provide the text of a schema directly in the reader/writer, or use EL to obtain it from a flow file attribute
- HWX Content-Encoded Schema Reference - The content of the FlowFile contains a reference to a schema in a Schema Registry service
- HWX Schema Reference Attributes - The FlowFile contains 3 Attributes that will be used to lookup a schema from the configured Schema Registry: ‘schema.identifier’, ‘schema.version’, and ‘schema.protocol.version’
The are currently two schema registry services provided:
- AvroSchemaRegistry - A schema registry local to a given NiFi instance that supports retrieving a schema by name
- HortonworksSchemaRegistry - An external Hortonworks Schema Registry instance that supports retrieving a schema by name, or by id and version
The Big Picture
Putting this all together, the interaction and hierarchy of readers, writers, and registries looks like the following:
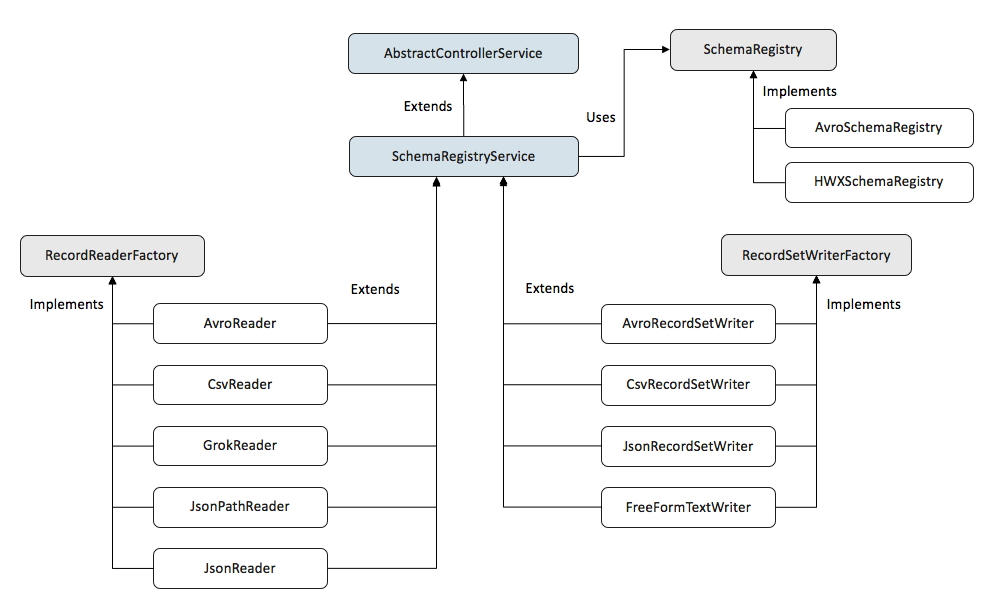
All of the reader and writer factories extend from SchemaRegistryService which is an abstract class containing common code for the Schema Access Strategy and obtaining a schema from a registry.
Record Processors
Now that we have readers, writers, and schema registries, it becomes straight-forward to provide a series of generic processors to handle records. By treating flow files as records, we can typically avoid the need to split the content of a flow file into many smaller flow files just for the sake of manipulating the data. This has the benefit of reducing the amount of updates to the flow file repository, reducing the number of provenance events generated, and reducing overall garbage collection, all of which can lead to significant performance improvements.
This list will likely be expanding over time, but at the time of writing this, the following record-related processors exist:
ConvertRecord
Converts between formats and/or like schemas. For example, conversion from CSV to Avro can be performed by configuring ConvertRecord with a CsvReader and an AvroRecordSetWriter. In addition, schema conversion between like schemas can be performed when the write schema is a sub-set of the fields in the read schema, or if the write schema has additional fields with default values.
LookupRecord
Extracts one or more fields from a Record and looks up a value for those fields in a LookupService. The results can then be added back to the record by specifying a destination record path, or can be ignored and used for routing to ‘matched’ or ‘unmatched’. For example, if the records of the flow file contain a field called ‘ip’ containing an IP address, we can add a property named ‘ip’ with a value as a record path ‘/ip’ and use an IPLookupService to enrich our records with information about the IP address.
PartitionRecord
Partitions the incoming flow file into groups of ‘like’ records by evaluating one or more user-supplied records paths against each record. For example, if the records have a field called ‘type’ and type can have values A, B, or C, we could use this processor to produce three flow files where one contains all the records with type A, one contains all the records with type B, and one contains all the records with type C.
QueryRecord
Executes a SQL statement against records and writes the results to the flow file content. The best way to explain this one is to read this blog post.
SplitRecord
Splits an incoming flow file into one or more flow files containing the desired record count. Similar to SplitText, but for records.
UpdateRecord
Updates a record by specifying a record path indicating the field to update, and a value to update the field with. The value can be a literal, or can be another record path expression of which the result would be used as the value. For example, to update field A with the value of field B, a user-defined property can be added with the name of ‘/A’ and a value of ‘/B’.
ConsumeKafkaRecord_0_10
Similar to ConsumeKafka_0_10, except this processor will use the configured record reader to deserialize the raw data retrieved from Kafka, and then use the configured record writer to serialize the records to the flow file content.
PublishKafkaRecord_0_10
Similar to PublishKafka_0_10, except this processor will use the configured record reader to read the incoming flow file as records, and then use the configured record writer to serialize each record for publishing to Kafka.
Record Processing Example
For an example, let’s read a log file using a GrokReader and convert it to JSON using a JsonRecordSetWriter, and lets demonstrate how to interact with the Hortonworks Schema Registry.
-
Download the latest registry release, currently 0.2.1
-
Extract the tar, build, and start the registry application
tar xzvf hortonworks-registry-0.2.1.tar.gz cd hortonworks-registry-0.2.1 ./bin/registry-server-start.sh conf/registry-dev.yaml -
Navigate to the registry UI in your browser
-
Add the following schema:
{ "type": "record", "name": "nifi_logs", "fields": [ { "name": "timestamp", "type": "string" }, { "name": "level", "type": "string" }, { "name": "thread", "type": "string" }, { "name": "class", "type": "string" }, { "name": "message", "type": "string" }, { "name": "stackTrace", "type": "string" } ] }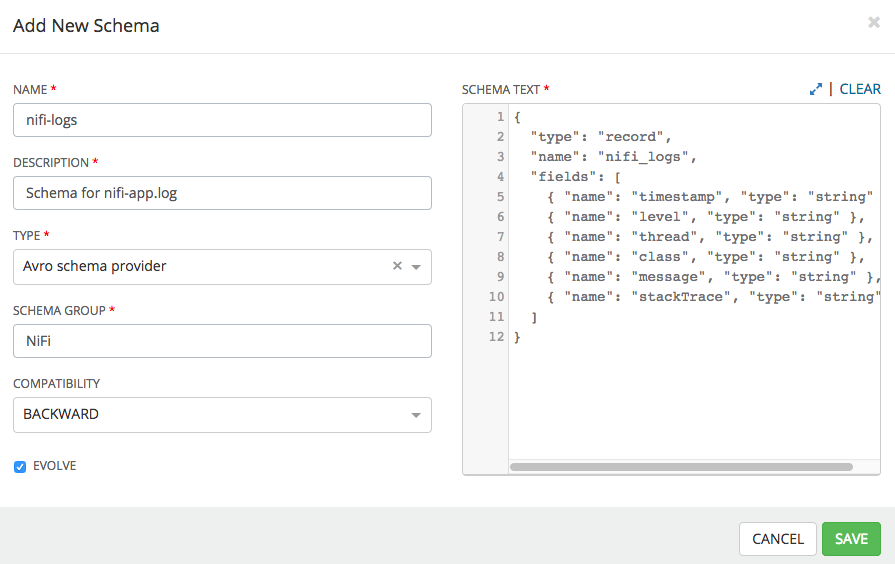
-
Download Apache NiFi 1.3.0
-
Extract and start NiFi 1.3.0
tar xzvf nifi-1.3.0-bin.tar.gz cd nifi-1.3.0 ./bin/nifi.sh start -
Navigate to the NiFi UI in your browser
-
Create controller services for Hortonworks Schema Registry, GrokReader, and JsonRecordSetWriter
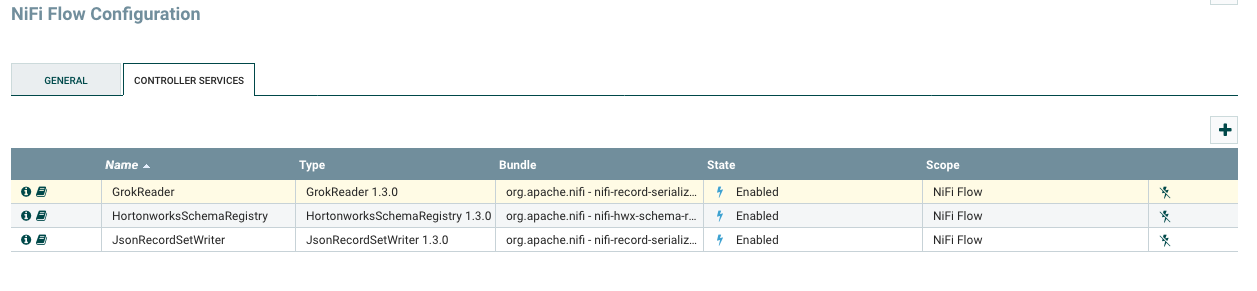
-
Configure the Hortonworks Schema Registry service to point to the local registry instance at http://localhost:9090/api/v1
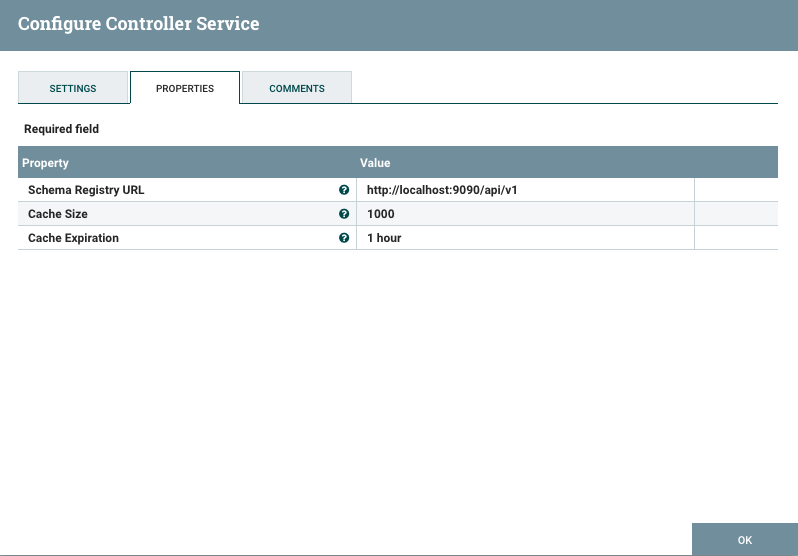
-
Configure the GrokReader to use the Hortonworks Schema Registry and provide the Grok expression
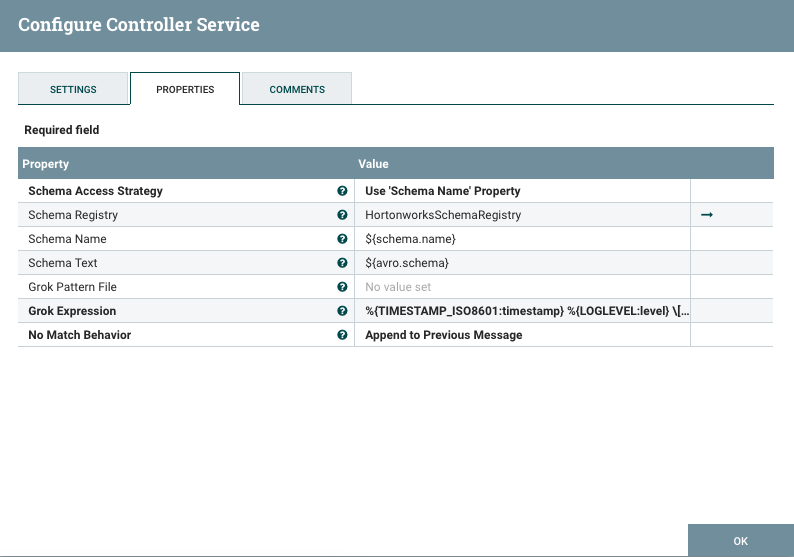
%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:level} \[%{DATA:thread}\] %{DATA:class} %{GREEDYDATA:message} -
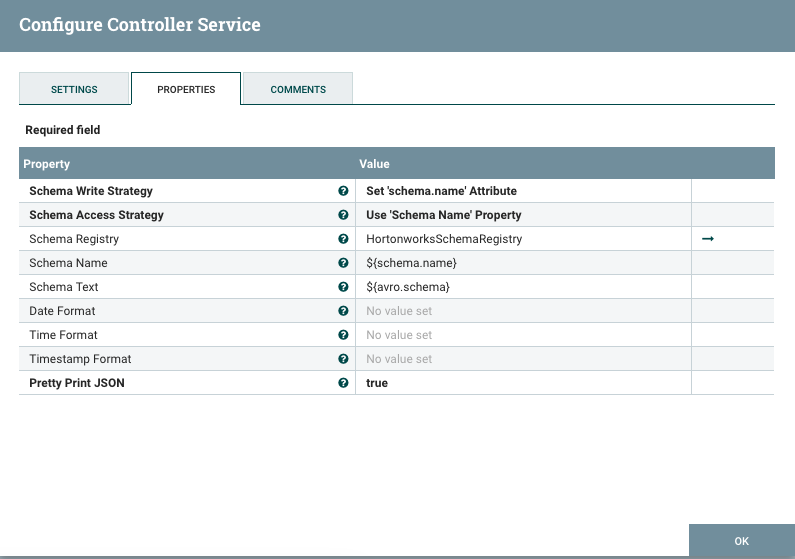
Configure the JsonRecordSetWriter to use the Hortonworks Schema Registry
-
Create a flow with TailFile, UpdateAttribute, ConvertRecord, and LogAttribute
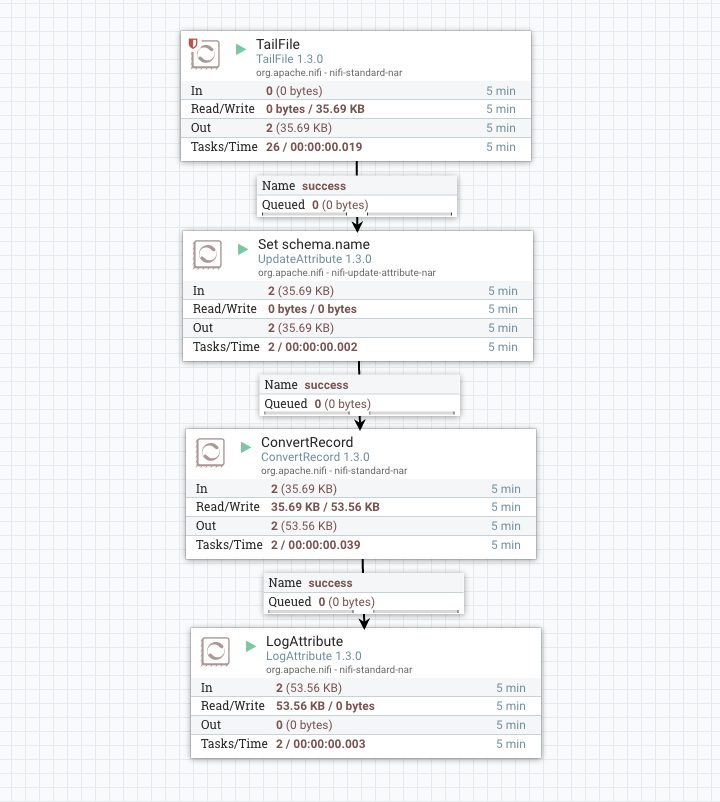
- TailFile is set to tail ./logs/nifi-user.log
- UpdateAttribute adds ‘schema.name’ set to ‘nifi-logs’ which corresponds to the name in the HWX Schema Registry
- ConvertRecord uses the GrokReader and JsonRecordSetWriter
- LogAttribute is set to Log Payload true
Now with this flow running, if we look in nifi-app.log we should see the logging from the LogAttribute processor which should show JSON corresponding to the log entries in nifi-user.log:
--------------------------------------------------
Standard FlowFile Attributes
Key: 'entryDate'
Value: 'Tue Jun 20 15:20:55 EDT 2017'
Key: 'lineageStartDate'
Value: 'Tue Jun 20 15:20:55 EDT 2017'
Key: 'fileSize'
Value: '1596'
FlowFile Attribute Map Content
Key: 'filename'
Value: 'nifi-user.158432-159491.log'
Key: 'mime.type'
Value: 'application/json'
Key: 'path'
Value: './'
Key: 'record.count'
Value: '5'
Key: 'schema.name'
Value: 'nifi-logs'
Key: 'tailfile.original.path'
Value: './logs/nifi-user.log'
Key: 'uuid'
Value: '38c2bacc-5b3d-4d7d-b71d-b717e4524402'
--------------------------------------------------
[ {
"timestamp" : "2017-06-20 15:20:55,017",
"level" : "INFO",
"thread" : "NiFi Web Server-142",
"class" : "org.apache.nifi.web.filter.RequestLogger",
"message" : "Attempting request for (anonymous) GET...",
"stackTrace" : null
}, {
"timestamp" : "2017-06-20 15:20:55,018",
"level" : "INFO",
"thread" : "NiFi Web Server-175",
"class" : "org.apache.nifi.web.filter.RequestLogger",
"message" : "Attempting request for (anonymous) GET...",
"stackTrace" : null
}, {
"timestamp" : "2017-06-20 15:20:55,025",
"level" : "INFO",
"thread" : "NiFi Web Server-150",
"class" : "org.apache.nifi.web.filter.RequestLogger",
"message" : "Attempting request for (anonymous) GET...",
"stackTrace" : null
}]
From there we could use QueryRecord to select only the records where the level was ERROR, or we could use PartitionRecord to divide the records into groups according to the level.
Conclusion
The record readers and writers provide a best-of-both-worlds approach where NiFi can still treat the content of flow files as arbitrary bytes, but then interpret those bytes as records when desired. Many use-cases become drastically simplified and more efficient by manipulating records in place, and the schema registry provides a central location to share schemas across the enterprise.
Be on the look out for more record-related capabilities in the future!
blog comments powered by Disqus