Apache NiFi - Optimizing Performance of Network Listening Processors
Apache NiFi provides several processors for receiving data over a network connection, such as ListenTCP, ListenSyslog, and ListenUDP. These processors are implemented using a common approach, and a shared framework for receiving and processing messages.
When one of these processors is scheduled to run, a separate thread is started to listen for incoming network connections. When a connection is accepted, another thread is created to read from that connection, we will call this the channel reader (the original thread continues listening for additional connections).
The channel reader starts reading data from the connection as fast as possible, placing each received message into a blocking queue. The blocking queue is a shared reference with the processor. Each time the processor executes it will poll the queue for one or more messages and write them to a flow file.
The overall setup looks like the following:
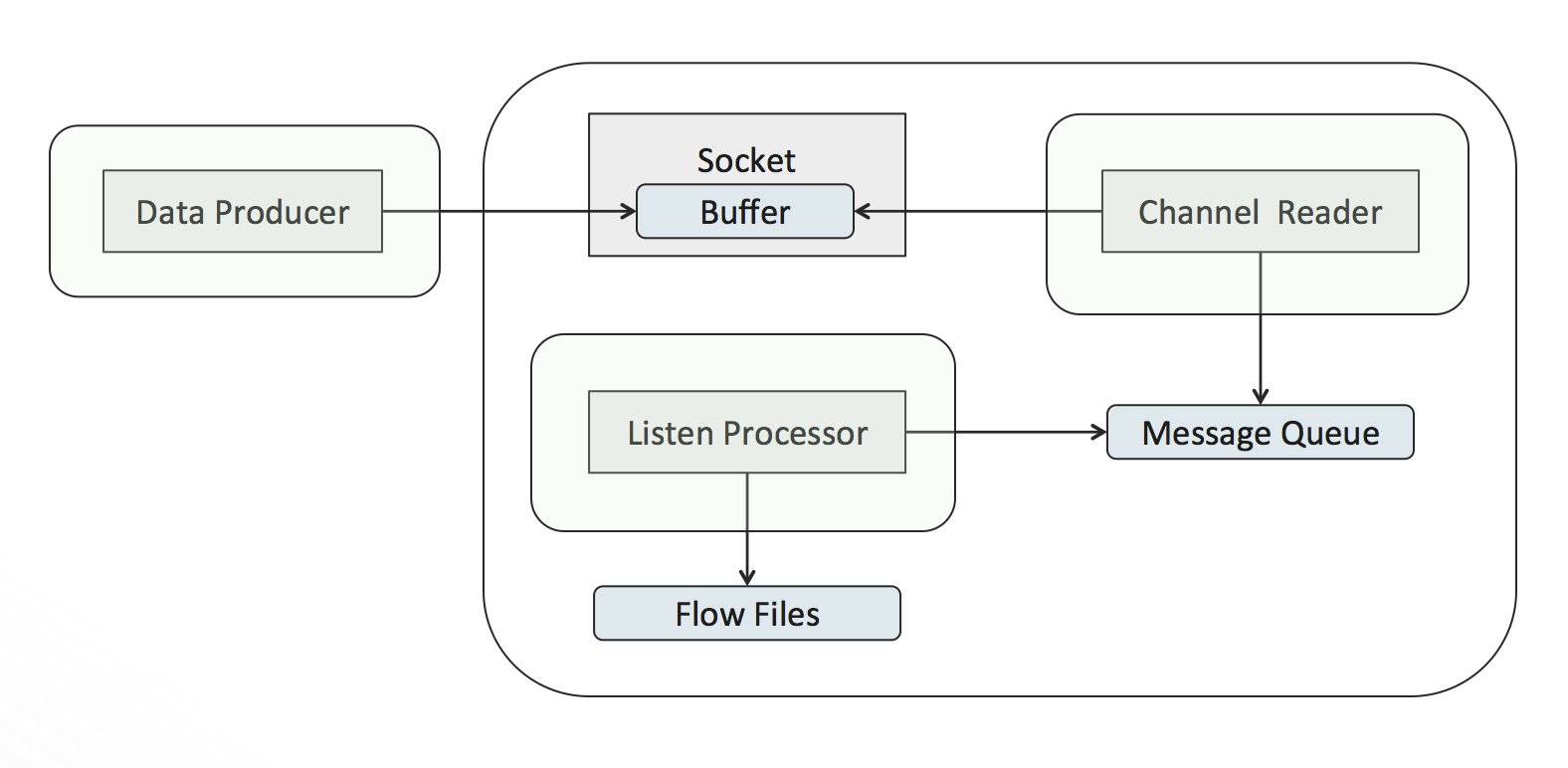
There are several competing activities taking place:
-
The data producer is writing data to the socket, which is being held in the socket’s buffer, while at the same time the channel reader is reading the data held in that buffer. If the data is written faster than it is read, then the buffer will eventually fill up, and incoming data will be dropped.
-
The channel reader is pushing messages into the message queue, while the processor concurrently pulls messages off the queue. If messages are pushed into the queue faster than the processor can pull them out, then the queue will reach maximum capacity, causing the channel reader to block while waiting for space in the queue. If the channel reader is blocking, it is not reading from the connection, which means the socket buffer can start filling up and cause data to be dropped.
In order to achieve optimal performance, these processors expose several properties to tune these competing activities:
-
Max Batch Size – This property controls how many messages will be pulled from the message queue and written to a single flow file during one execution of the processor. The default value is 1, which means a message-per–flow-file. A single message per flow file is useful for downstream parsing and routing, but provides the worst performance scenario. Increasing the batch size will drastically reduce the amount I/O operations performed, and will likely provide the greatest overall performance improvement.
-
Max Size of Message Queue – This property controls the size of the blocking queue used between the channel reader and the processor. In cases where large bursts of data are expected, and enough memory is available to the JVM, this value can be increased to allow more room for internal buffering. It is important to consider that this queue is held in memory, and setting this size too large could adversely affect the overall memory of the NiFi instance, thus causing problems for the overall flow and not just this processor.
-
Max Size of Socket Buffer – This property attempts to tell the operating system to set the size of the socket buffer. Increasing this value provides additional breathing room for bursts of data, or momentary pauses while reading data. In some cases, configuration may need to be done at the operating system level in order for the socket buffer size to take affect. The processor will provide a warning if it was not able to set the buffer size to the desired value.
-
Concurrent Tasks – This is a property on the scheduling tab of every processor. In this case, increasing the concurrent tasks means more quickly pulling messages off the message queue, and thus more quickly freeing up room for the channel reader to push more messages in. When using a larger Max Batch Size, each concurrent task is able to batch together that many messages in a single execution.
Adjusting the above values appropriately should provide the ability to tune for high through put scenarios. A good approach would be to start by increasing the Max Batch Size from 1 to 1000, and then observe performance. From there, a slight increase to the Max Size of Socket Buffer, and increasing Concurrent Tasks from 1 to 2, should provide additional improvements.
blog comments powered by Disqus