Apache NiFi - Stateless
The past several releases of Apache NiFi have made significant improvements to the Stateless NiFi engine. If you are not familiar with Stateless NiFi, then I would recommend reading this overview first.
This post will examine the differences between running a flow in traditional NiFi vs. Stateless NiFi.
Traditional NiFi
As an example, let’s assume there is a Kafka topic with CDC events and we want to consume the
events and apply them to another relational database. This can be achieved with a simple flow
containing ConsumeKafka_2_6 connected to PutDatabaseRecord.
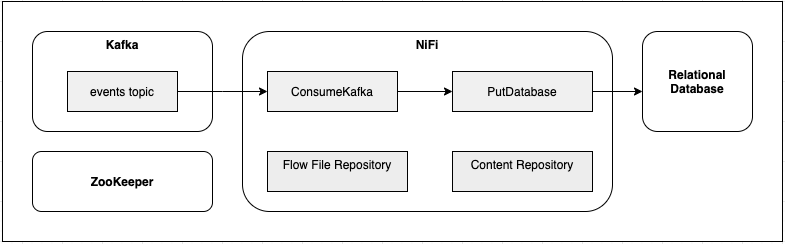
In traditional NiFi, each node has a set of internal repositories that are stored on local disk. The Flow File Repository contains the state of each flow file, including its attributes and location in the flow, and the Content Repository stores the content of each flow file.
Each execution of a processor is given a reference to a session that acts like a transaction for operating on flow files. If all operations complete successfully and the session is committed, then all updates are persisted to NiFi’s repositories. In the event that NiFi is restarted, all data is preserved in the repositories and the flow will start processing from the last committed state.
Let’s consider how the example flow will execute in traditional NiFi…
First, ConsumeKafka_2_6 will poll Kafka for available records. Then it will use the session to create a flow file
and write the content of the records to the output stream of the flow file. The processor will then commit the NiFi
session, followed by committing the Kafka offsets. The flow file will then be transferred to PutDatabaseRecord. The
overall sequence is summarized in the following diagram.
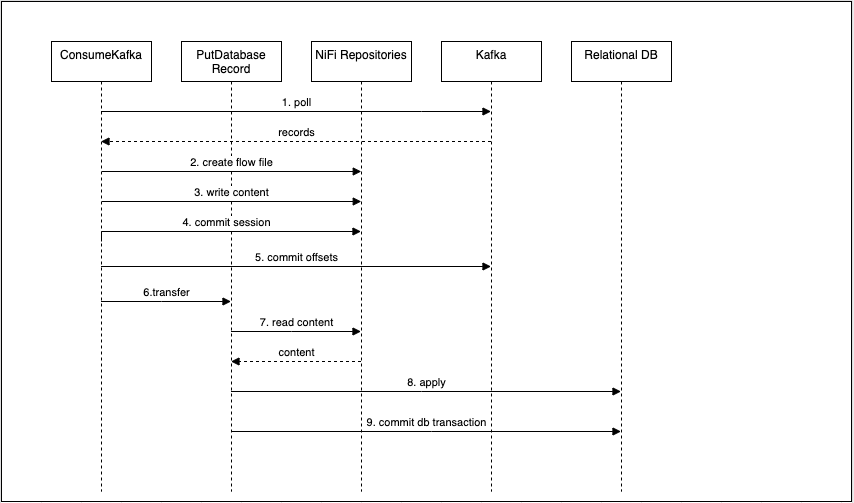
A key point here is the ordering of committing the NiFi session before committing the Kafka offsets. This provides an “at least once” guarantee by ensuring the data is persisted in NiFi before acknowledging the offsets. If committing the offsets fails, possibly due to a consumer rebalance, NiFi will consume those same offsets again and receive duplicate data. If the ordering was reversed, it would be possible for the offsets to be successfully committed, followed by a failure to commit the NiFi session, which would create data loss and be considered “at most once”.
A second key point is that there is purposely no coordination across processors, meaning that each processor succeeds or fails
independently of the other processors in the flow. Once ConsumeKafka_2_6 successfully executes, the consumed data is now persisted
in NiFi, regardless of whether PutDatabaseRecord succeeds.
Let’s look at how this same flow would execute in Stateless NiFi.
Stateless NiFi
Stateless NiFi adheres to the same NiFi API as traditional NiFi, which means it can run the same processors and flow definitions, it just provides a different implementation of the underlying engine.
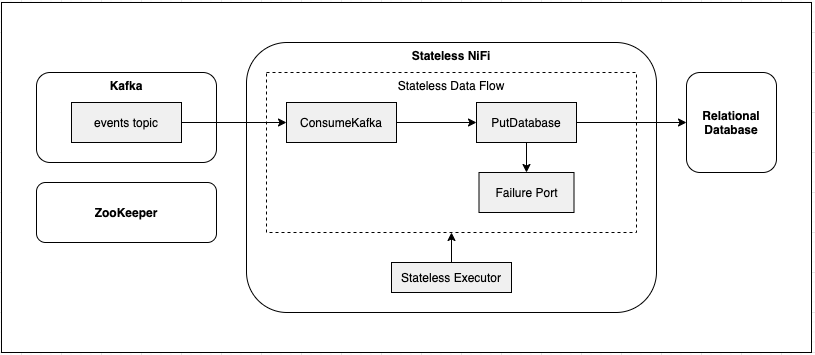
The primary abstraction is a StatelessDataFlow which can be triggered to execute. Each execution of the flow
produces a result that can be considered a success or failure. A failure can occur from a processor throwing an exception,
or from explicitly routing flow files to a named “failure port”.
A key difference in Stateless NiFi is around committing the NiFi session. A new commit method was introduced
to ProcessSession with the following signature:
void commitAsync(Runnable onSuccess);
This gives the session implementation control over when to execute the given callback. In traditional NiFi the session can execute the
callback as the last step of commitAsync, which produces the same behavior we looked at earlier. The stateless NiFi session can
hold the callback and execute it only when the entire flow has completed successfully.
Let’s consider how the example flow will execute in Stateless NiFi…
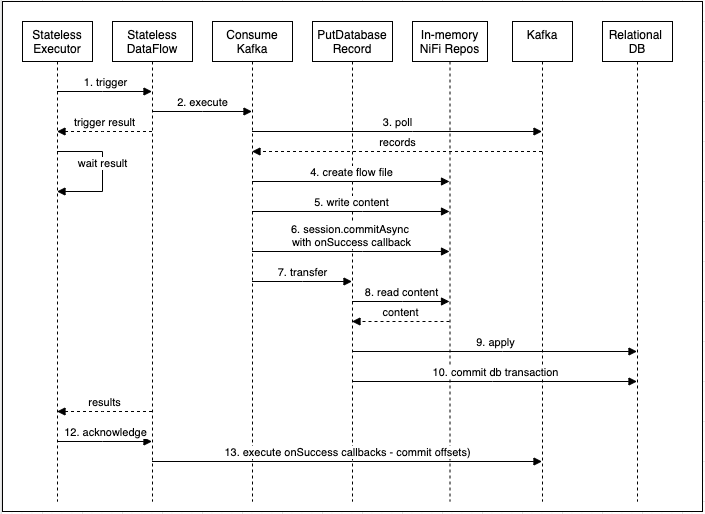
When the StatelessDataFlow is triggered, ConsumeKafka_2_6 begins executing the same as it would in traditional NiFi, by polling
Kafka for records, creating a flow file, and writing the records to the output stream of the flow file. It then calls commitAsync to
commit the NiFi session and passes in a callback for committing the offsets to Kafka, which in this case will be held until later.
The flow file is then transferred to PutDatabaseRecord which attempts to apply the event to the database. Let’s assume
PutDatabaseRecord was successful, then the overall execution of the flow completes successfully. The stateless engine then
acknowledges the result which executes any held callbacks, and thus commits the offsets to Kafka. The overall sequence is
summarized in the following diagram.
A key point here is that the execution of the entire flow is being treated like a single transaction. If a failure were to occur at
PutDatabaseRecord, the overall execution would be considered a failure, and the onSuccess callbacks from commitAsync
would never get executed. In this case, that would mean the offsets were never committed to Kafka, and the entire flow can be tried
again for the same records.
Another type of failure scenario would be if Stateless NiFi crashed in the middle of executing the flow. Since Stateless NiFi generally uses in-memory repositories, any data that was in the middle of processing would be gone. However, since the source processor had not yet acknowledged receiving that data (i.e. the onSuccess callback never got executed), it would pull the same data again on the next execution.
ExecuteStateless
Previously, the primary mechanism to use Stateless NiFi was through the nifi-stateless binary which launches a standalone process to
execute the flow.
The 1.15.0 release introduced a new processor called ExecuteStateless which can be used to run the Stateless engine from within traditional
NiFi. This allow you to manage the execution of the Stateless flow using the traditional NiFi UI, as well as connect the output of the Stateless flow to follow on processing in the traditional NiFi flow.
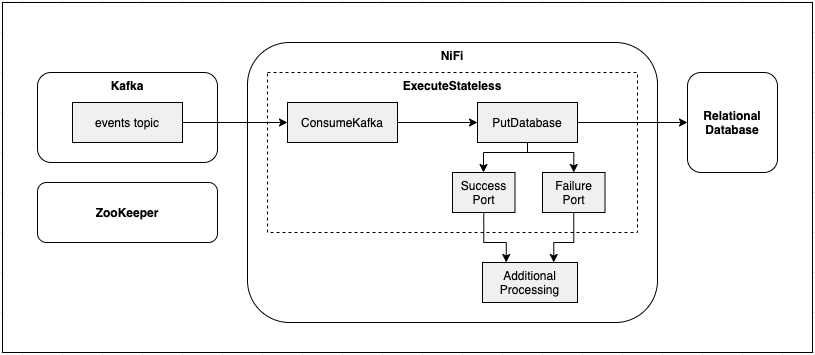
In order to use the ExecuteStateless processor, you would first use traditional NiFi to create a process group containing the flow
you want to execute with the Stateless engine. You would then download the flow definition, or commit the flow to a NiFi Registry instance.
From there, you would configure ExecuteStateless with the location of the flow definition.
For a more in depth look at ExecuteStateless, check out Mark Payne’s YouTube Video on “Kafka Exactly Once with NiFi”.
blog comments powered by Disqus